La GeForce RTX 4090 exploite un GPU AD102 issu d’un processus de fabrication 4N de TSMC. Il se compose de 76.3 milliards de transistors répartis sur une surface de 608 mm²

GPU AD102, architecture ADA LoveLace
Ce processeur graphique exploite l’architecture graphique Ada Lovelace. Son interface haute est en PCI-Express 4.0 x16 tandis qu’il gère de la mémoire GDDR6X au travers d’un bus 384-bit.

Le diagramme proposé par Nvidia dévoile une organisation profitant du moteur Gigathread en charge d’allouer les ressources. L’architecture Ada Lovelace dispose d’un module nommé OFA contraction d’Optical Flow Accelerator. Nous verrons en fin d’article qu’il joue un rôle essentiel pour la technologie DLSS de troisième génération. Il génère des images entières grâce à l’IA sans solliciter la machinerie de rendu graphique.
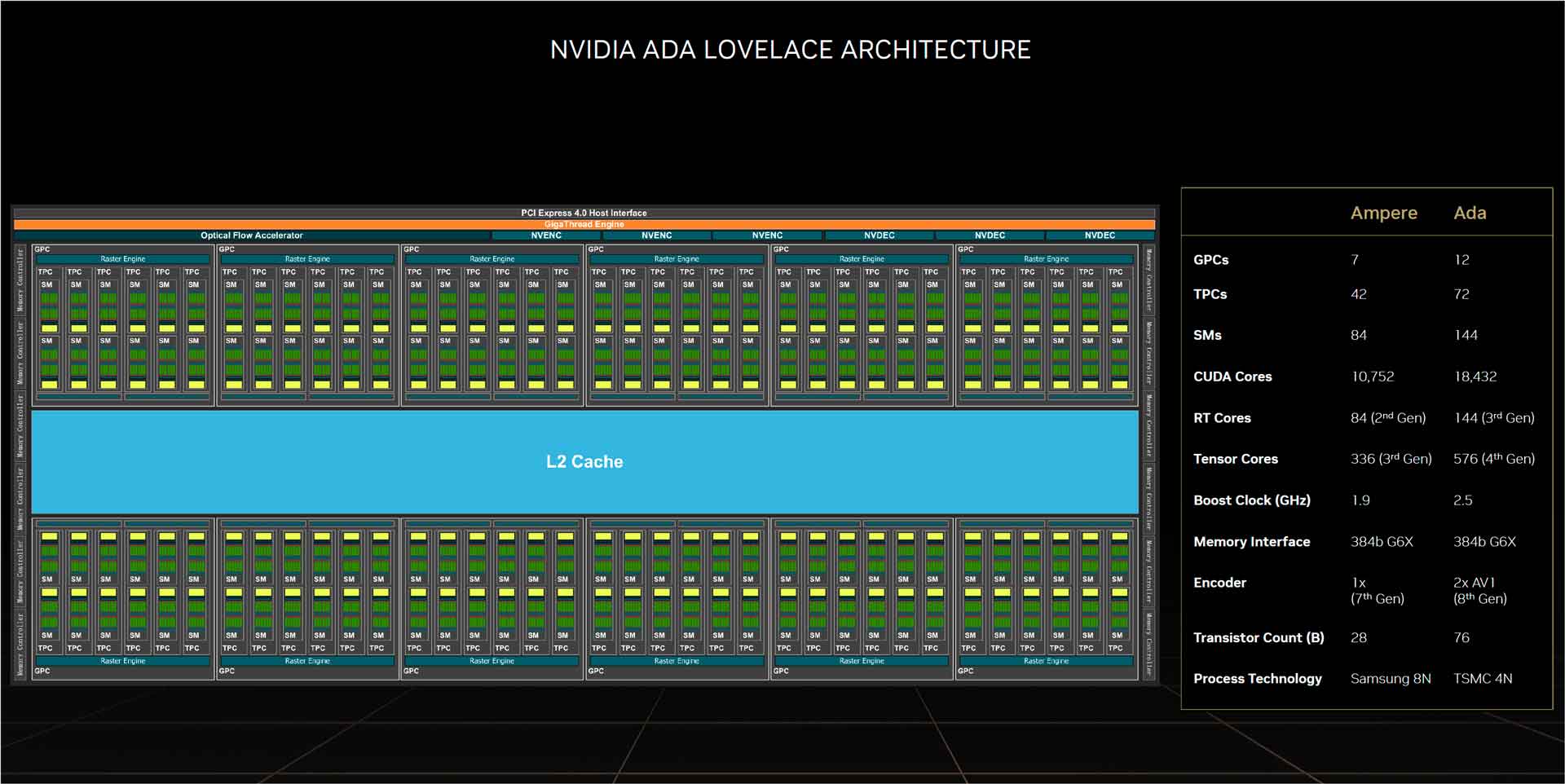
La puce embarque deux fois plus d’unités d’encodage multimédia qu’« Ampere ». Cela comprend l’accélération matérielle de l’encodage et décodage AV1. Ce choix améliore les performances dans un contexte de production. La présence de plus d’unités d’encodage multimédia signifie plus de flux de vidéos pouvant être traités en même temps. Les principaux composants de rendu graphique de l’AD102 sont les GPC alias les graphics processing clusters. Nous en retrouvons 12 contre 7 pour le GA102 (Ampere). Il se compose d’un moteur Raster et de 6 TPC (texture processing clusters). Chaque TPC contient deux SM (multiprocesseurs de streaming).
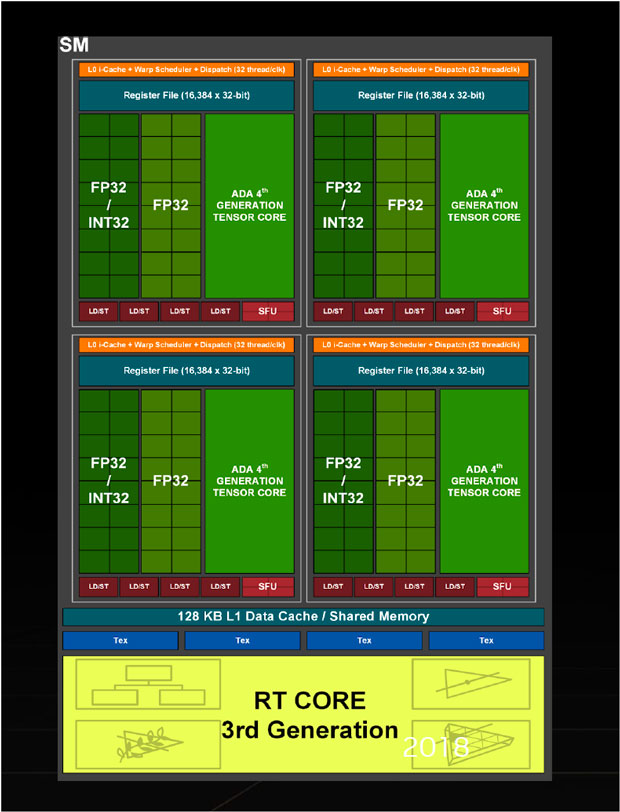
Nvidia explique que les SM ont été retravaillés. Chaque SM contient un cœur RT de 3e génération, un cache L1 de 128 Ko et quatre TMUs. Nous observons 16 cœurs CUDA (FP32), 16 cœurs CUDA (FP32 + INT32), 4 unités de LD/ST (chargement / stockage), un petit cache L0 épaulé du « Warp Sheduler » et du « dispatch » ainsi qu’un fichier de registre et un noyau Tensor de 4e génération.
Du coup par simple multiplication, un SM embarque 128 cœurs CUDA, 4 cœurs Tensor et un cœur RT. Sachant qu’il y a 12 SM par GPC, nous retrouvons un total de 1 536 cœurs CUDA, 48 cœurs Tensor et 12 cœurs RT par GPC soit pour un ensemble de douze GPC 18 432 cœurs CUDA, 576 cœurs Tensor et 144 cœurs RT.
NVIDIA n’a pas mentionné la taille du cache L2, mais il est censé être plus imposant que celui de la génération Ampere.
Architecture Ada LoveLace
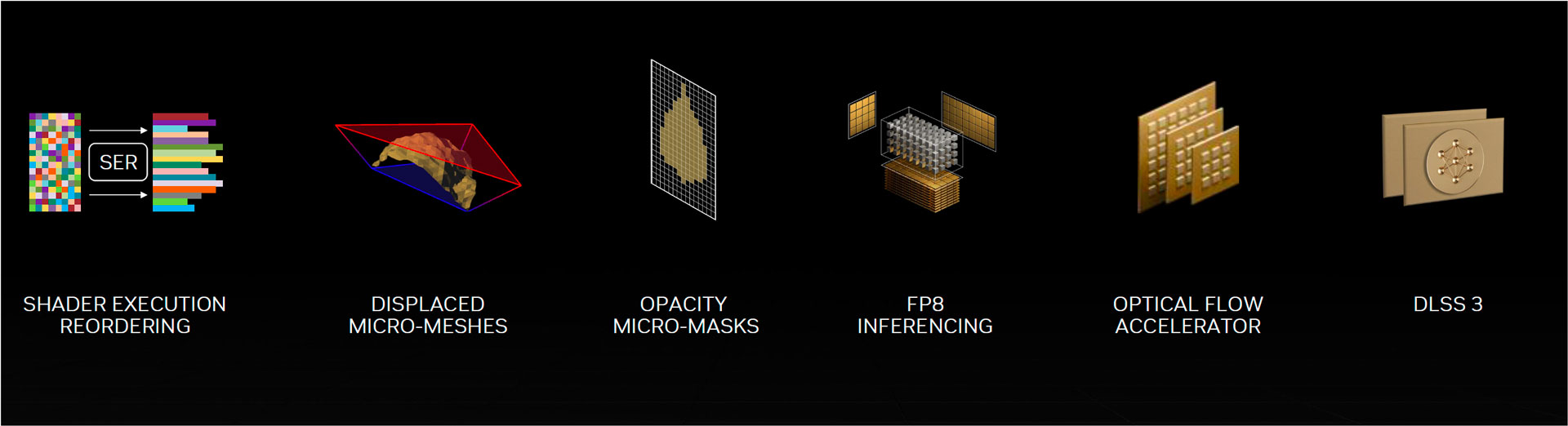
Shader Execution Reordering
Ada Lovelace profite également d’une réorganisation de l’exécution sharder (SER). L’idée est de réarranger en amont, pour chaque thread de travail, les charges de travail mathématique afin qu’elles soient traitées le plus efficacement possible par les composants SIMD. Il est promis un impact sur les performances en Rastérisation mais surtout en Ray Tracing. Pourquoi ?

Les performances sont optimales lorsqu’une même opération peut être traitée pour plusieurs cibles. Cela diminue la charge de traitement. En Ray Tracing, chaque rayon engendre un grand nombre de besoins de traitement différents. L’action du SER est de « trier » les opérations pour créer des morceaux de tâches identiques et de les exécuter. L’impact peut être très important. Par exemple sous Cyberpunk 2077, la technologie SER améliore les performances jusqu’à 44% et 29 % avec Portal RTX.
Lors de sa présentation, Nvidia a souhaité souligner que cette technologie est adaptable et modulable. Il existe différentes approches pour le SER et le meilleur choix varie selon le jeu. L’API proposera un contrôle sur le fonctionnement de l’algorithme de tri.
Displaced Micro-Meshes
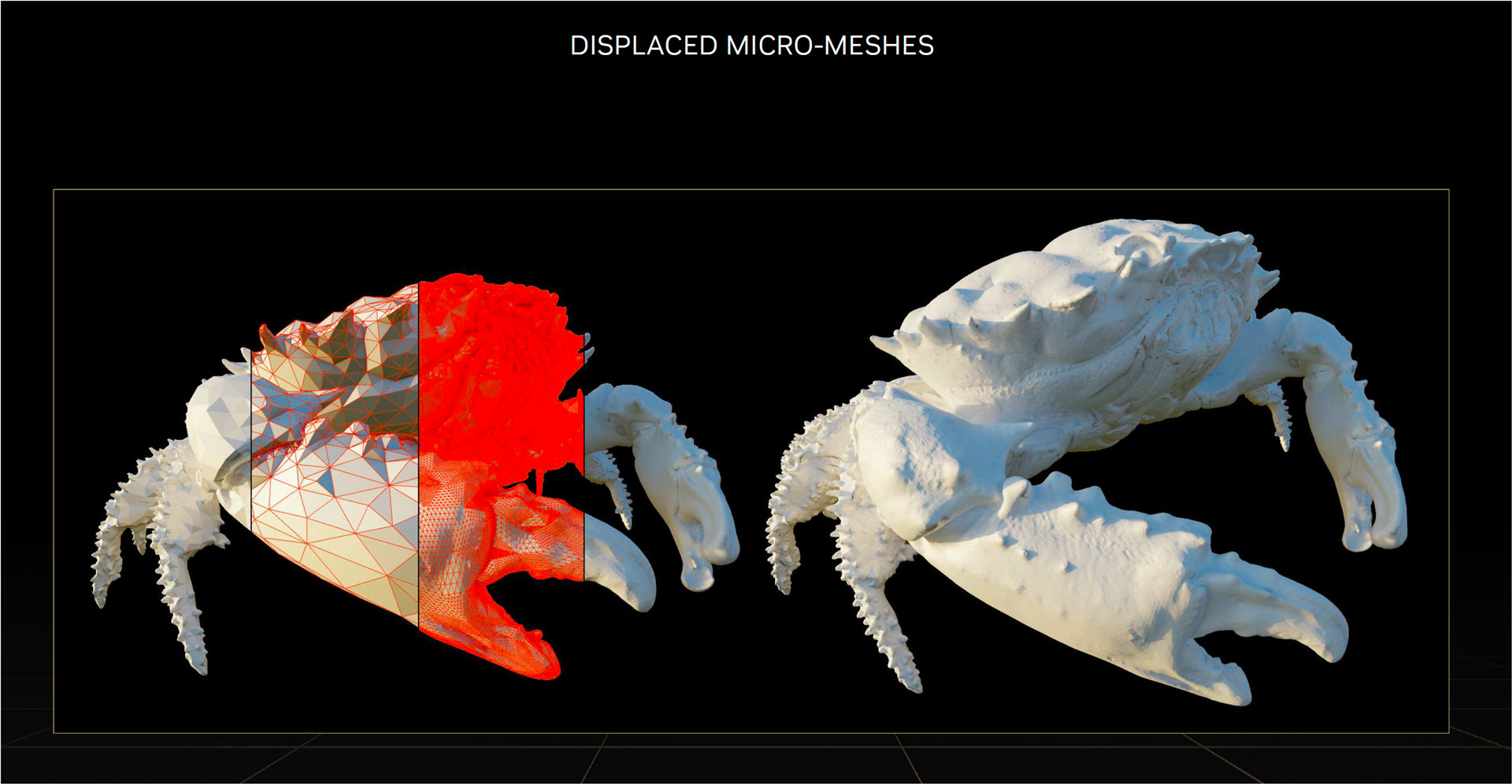
Ada Lovelace profite également d’un moteur de micro-maillage déplacé (Displaced Micro-Meshes) assuré par les cœurs RT de 3e génération. Ces DIMMs élaborent les hiérarchies de volumes englobants (BVH alias Bounding-Volume Hierarchy) de manière plus efficace et moins gourmande en ressource. Nvidia évoque une vitesse accrue d’un facteur 10 et des besoins en mémoire vidéo divisés par 20. Ce maillage structuré de micro-triangles est traité en natif par les cœurs RT de 3ième génération.
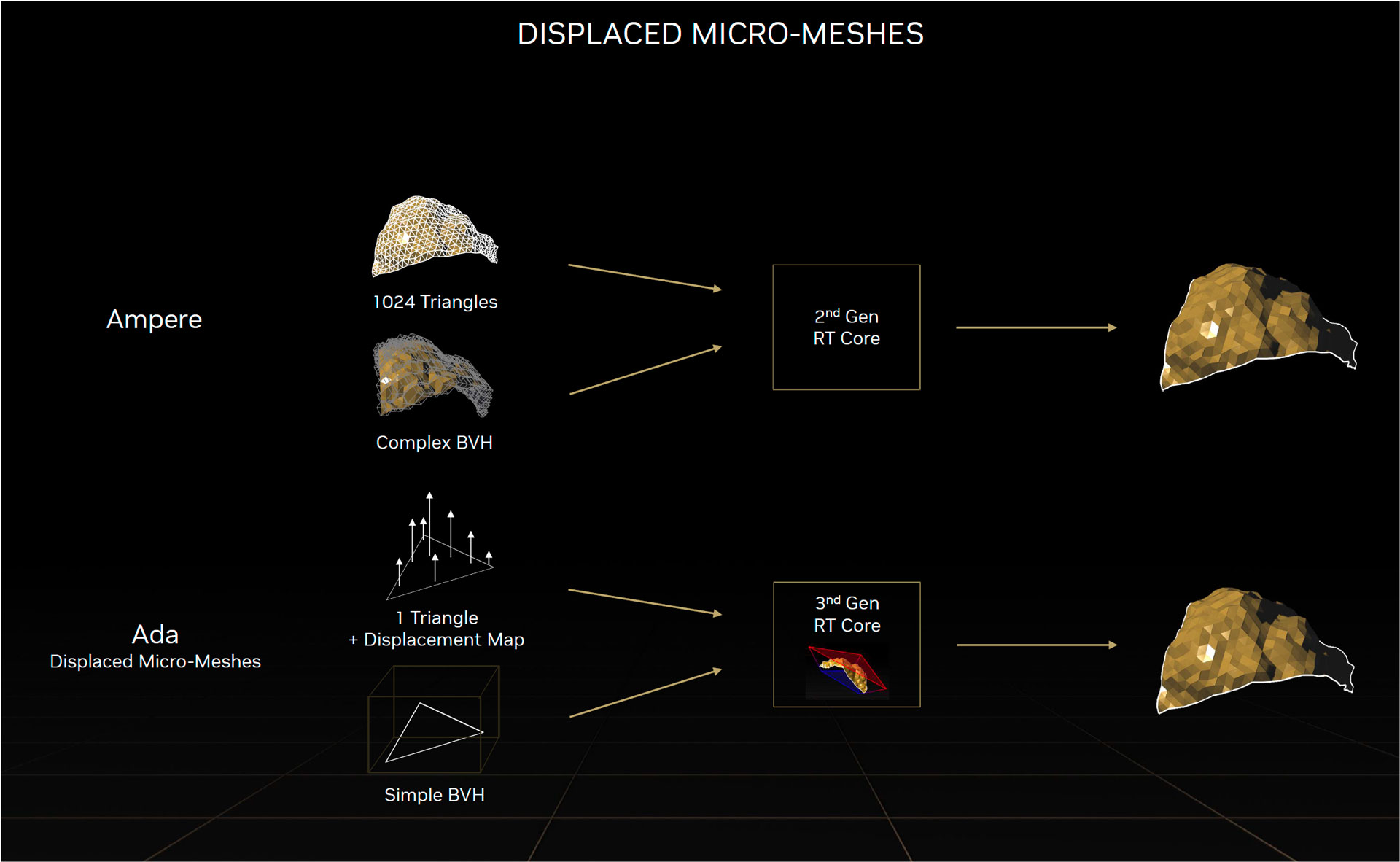
L’approche est de représenter des objets à géométrie complexe sous la forme d’un maillage grossier d’un triangle de base. La structure de données BVH se simplifie ce qui soulage les besoins en mémoire et réduit la charge du processeur de ray tracing. Contrairement à Ampere, où les Core RT de 2ième génération doivent traiter toutes les informations de chaque triangle format le maillage, les Core RT de 3ième génération d’Ada LoveLace traitent un triangle accompagné d’un map permettant de reconstruire l’objet et ses interactions avec la lumière.
Les gains se situent à plusieurs échelles, de quoi soulager les besoins en:
- bande passante,
- stockage,
- bus PCIe,
- et ressource processeur.
Opacity Micro Meshes
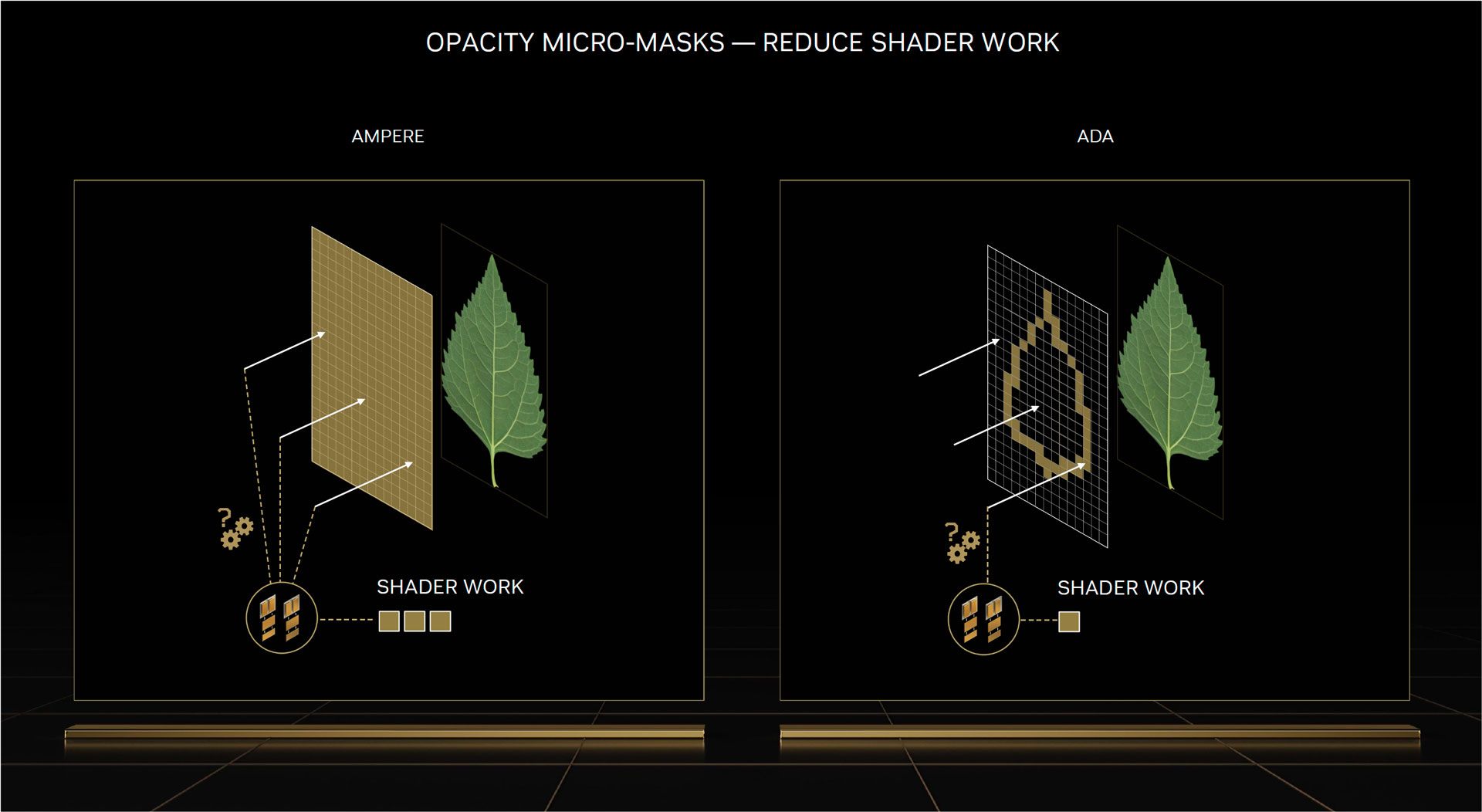
Nous avons également la fonctionnalité OMM alias l’Opacity Micro Meshes visant à booster les performances de pixellisation, en particulier avec les objets qui ont une valeur « alpha » (données de transparence). Certains objets composant une scène 3D, tels que les feuilles d’un arbre ont une forme difficile à maitriser pour les cœurs RT en charge de déterminer les interactions avec les rayons de lumière. Les feuilles sont essentiellement des rectangles exploitant des textures mais accompagnés d’un alpha (de transparence). Il permet de créer la forme de la feuille.
Les cœurs RT se retrouvent dans une situation complexe puisque la gestion des rayons avec de tels objets demande de connaitre la forme. Les cœurs RT Ampere ont besoin de plusieurs interactions pour déterminer cette forme. La situation a été résolue avec cette fonctionnalité OMM. Elle créé un maillage de textures rectangulaires qui s’alignent avec les parties de la texture sans donnée alpha. Du coup, les cœurs RT appréhendent mieux la forme exacte de l’objet à traiter. La méthode profite aussi à l’ombrage dans de rendu sans Ray Tracing.
DLSS 3
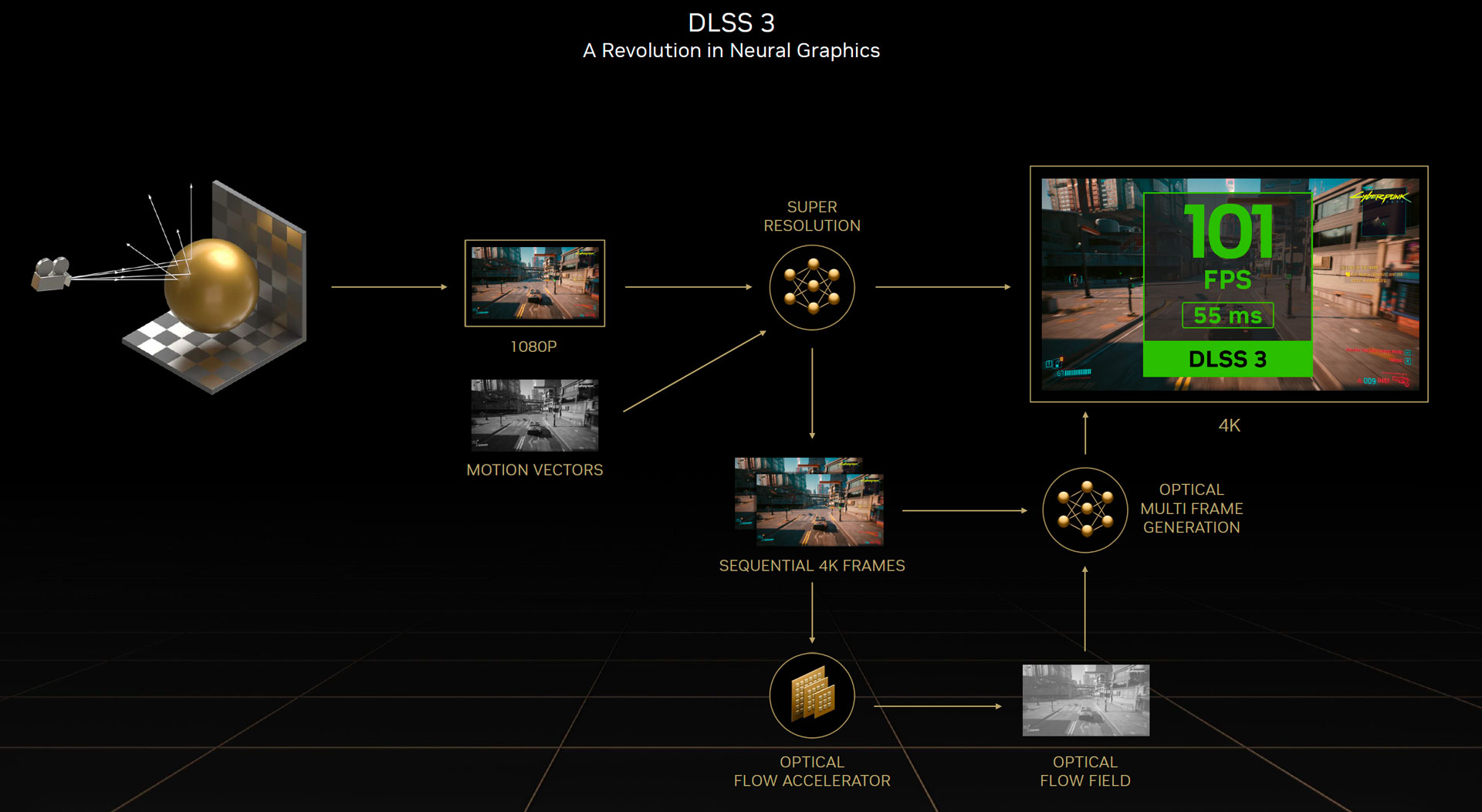
Enfin, la technologie DLSS 3 promet de doubler le nombre d’images par seconde à qualité comparable. Ceci est possible en raison d’une nouvelle avancée nommée AI frame-génération. Le DLSS 3 s’appuie sur le fonctionnement du DLSS 2 tout en générant des images entières de demi trame à l’aide de l’IA. De plus, ces images alternées sont le résultat d’une analyse des trames précédentes et suivantes.

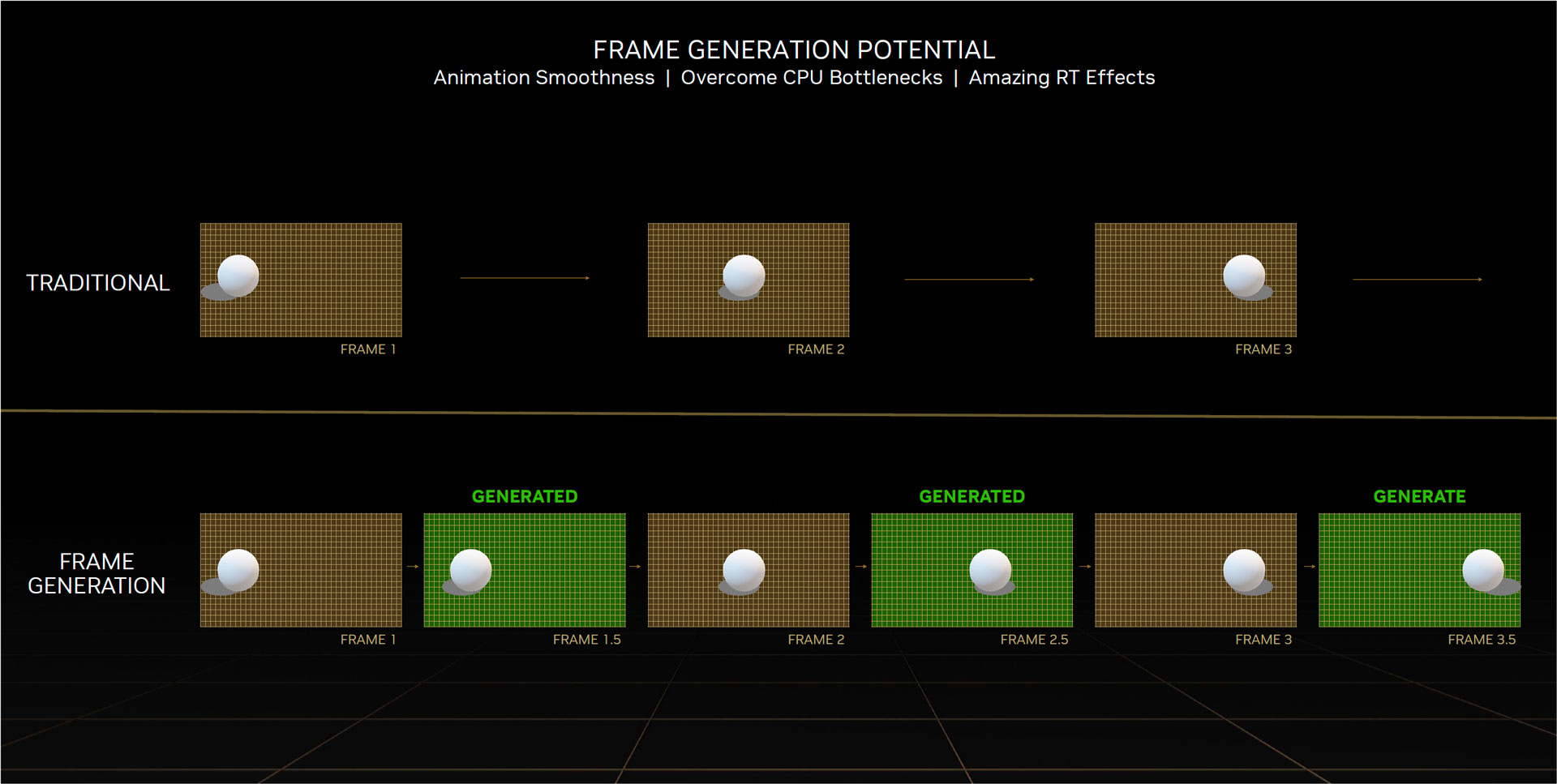
Cela n’est cependant possible que sur l’architecture graphique Ada lovelace, en raison d’un composant matériel , l’OFA (Optical flow accelerator). Il apporte son aide à prédire la prochaine image en créant un champ de flux optique (Optical flow-field). Son rôle est de permettre au DLSS 3 de connaitre les objets statiques dans une scène 3D dynamique. Ce processus s’appuie sur le format mathématique FP8 pris en charge par les coeurs Tensor de 4e génération. A noter que pour réduire la latence inhérente à cette avancée le DLSS 3.0 s’appuie sur Reflex.